
안녕하세요 주갬입니다.
작년에 이어 올해도 AWS Summit에 참석하여 다양한 강연을 들었습니다. 오늘은 이에 대한 후기를 작성해보려고 합니다.
행사는 5/16 ~ 5/17 양일간 진행되며, 17일은 생성형 AI 중심으로 강연이 구성되었습니다.
저는 생성형 AI에 관심이 많아 17일에만 참석하였습니다.
목차 )
- 키노트
- 생성형 ai 의 성공적 구축을 위한 데이터 전략
- AWS 스토리지로 AI/ML 워크로드 가속화하기
- 스마트한 미래, AWS와 함께하는 MongoDB Atlas 기반의 AI 애플리케이션 혁명
- Amazon BedRock을 이용한 프롬프트 엔지니어링 모범사례
- Imply Druid를 활용한 실시간 데이터 분석과 당근마켓 사례
- 부스 탐방
1. 키노트

키노트는 웅장한 4면 스크린에 영상으로 송출되었습니다. 이때부터 약간 스케일에 압도당하는 느낌이 들었습니다 ㅎ

다양한 분들이 연설을 해주셨지만 오늘 키노트에서는 클라우드 환경에서의 비용 효율성을 중점으로 얘기하였습니다. 비용을 최적화하는 효율적인 방법, 기업들의 사례 등을 기업 대표들이 직접 소개하였습니다. Frugal Architect, 플랫폼 엔지니어링, 생성형 AI등에 대한 내용도 있었습니다.
[자세한 내용]
비용 효율성, 지속성, 측정의 중요성, 플랫폼 엔지니어링, 그리고 생성형 AI에 대한 다양한 주제들이 다루어졌습니다. 아래는 각 주제에 대한 세부 내용입니다.
비용 효율성과 지속성
비용 효율성과 지속성은 현대 기술 아키텍처의 핵심 요소로 강조되었습니다. 특히 Frugal Architect 환경에서의 효율성에 대해 논의하며, 다음과 같은 중요한 사항들이 제시되었습니다:
- 비용을 비기능적 요구사항으로 고려: 시스템 설계 초기 단계부터 비용을 고려해야 하며, 이는 비기능적 요구사항으로 간주되어야 합니다.
- 비즈니스 비용에 맞는 시스템 설계: 규모의 경제를 활용하여 비즈니스 비용에 맞춘 시스템 설계를 해야 합니다.
- 아키텍처 설계의 타협: 아키텍처 설계는 항상 타협의 연속이며, 모든 결정에는 장단점이 존재함을 인식해야 합니다.
측정의 중요성
비용 인식 아키텍처와 비용 최적화의 중요성도 강조되었습니다. 주요 내용은 다음과 같습니다:
- 비용 최적화는 작은 단위의 최적화에서 시작: 누적된 작은 단위의 최적화가 전체 시스템의 비용 효율성을 크게 향상시킬 수 있습니다.
- 제약조건을 도전과제로 인식: 제약조건을 도전과제로 받아들이고 이를 극복함으로써 더 나은 결과를 도출할 수 있습니다.
Frugal Architect 사례
인프랩의 CTO가 발표한 내용에 따르면, 비즈니스 비용에 맞춘 시스템 설계의 중요성에 대해 많은 공감을 얻었습니다. 이는 효율적이고 경제적인 시스템 설계가 비즈니스 성공의 중요한 요소임을 다시 한번 확인시켜 주었습니다.
플랫폼 엔지니어링
카카오페이 증권 실장은 플랫폼 엔지니어링 조직의 생산성 향상과 인프라 혁신, 비즈니스 경쟁력 강화를 위한 전략에 대해 발표했습니다. 주요 내용은 다음과 같습니다:
- 쿠버네티스 도입 배경: 트래픽 변동을 오토스케일링만으로 관리할 수 없기 때문에 인프라 변동이 필요할 때 이를 기록하여 스케일 인/아웃을 지원하는 시스템을 도입하게 되었습니다.
- 단계적 접근: 플랫폼 엔지니어링은 단기적으로 성과를 내기 어려우며, 단계적이고 구체적으로 접근해야 달성할 수 있다는 점이 강조되었습니다.
생성형 AI
AWS에서 진행한 생성형 AI 관련 발표에서는 생성형 AI 스택에 대한 논의가 있었습니다. 주요 내용은 다음과 같습니다:
- 생성형 AI 스택: Nitro, Bedrock, Amazon Q 등의 기술이 언급되었습니다.
- 보안과 혁신: 보안이 최우선이라는 점과 혁신의 중요성이 강조되었습니다.
- 데이터의 가치: 자신의 데이터 가치를 인식하고 틀에 갇히지 말라는 메시지가 전달되었습니다.
2. 생성형 AI 의 성공적 구축을 위한 데이터 전략 (11:10 - 11:50)

첫번째 세션은 AWS의 이종혁, 진교선님이 발표하신 생성형 AI를 위해서 필요한 데이터를 어떻게 관리할 지에 대한 강의였습니다.
생성형 AI 애플리케이션의 성공적인 구현을 위해서는 데이터 통합과 활용이 필수적이며, RAG, 사전 훈련된 모델의 미세 조정, 지속적 사전 훈련 등 다양한 방법을 통해 비즈니스와 고객을 깊이 이해하는 AI 솔루션을 제공할 수 있습니다. 이를 통해 기업은 경쟁력을 강화하고 차별화된 서비스를 제공할 수 있습니다.
[자세한 내용]
생성형 AI 애플리케이션은 빙산의 일각에 불과하며, 데이터가 곧 차별화 요소입니다. 범용적인 생성형 AI에서 비즈니스와 고객을 깊이 이해하는 생성형 AI로의 전환이 중요합니다. 아래는 생성형 AI의 활용 사례와 이를 구현하는 방법들에 대해 설명합니다.
데이터 통합과 활용의 중요성
생성형 AI 애플리케이션의 성공은 데이터 통합과 활용에 크게 의존합니다. 데이터는 비즈니스 경쟁력의 핵심 요소이며, 이를 통해 차별화된 AI 솔루션을 제공할 수 있습니다. 데이터 통합의 중심에는 Redshift와 같은 솔루션이 있으며, 이는 시의성 있는 데이터 수집과 처리를 가능하게 합니다. 배치 및 스트리밍 방식으로 데이터를 수집하고 처리하는 것은 서버리스, 관리형, 통합 솔루션을 통해 이루어집니다.
RAG (Retrieval-Augmented Generation)
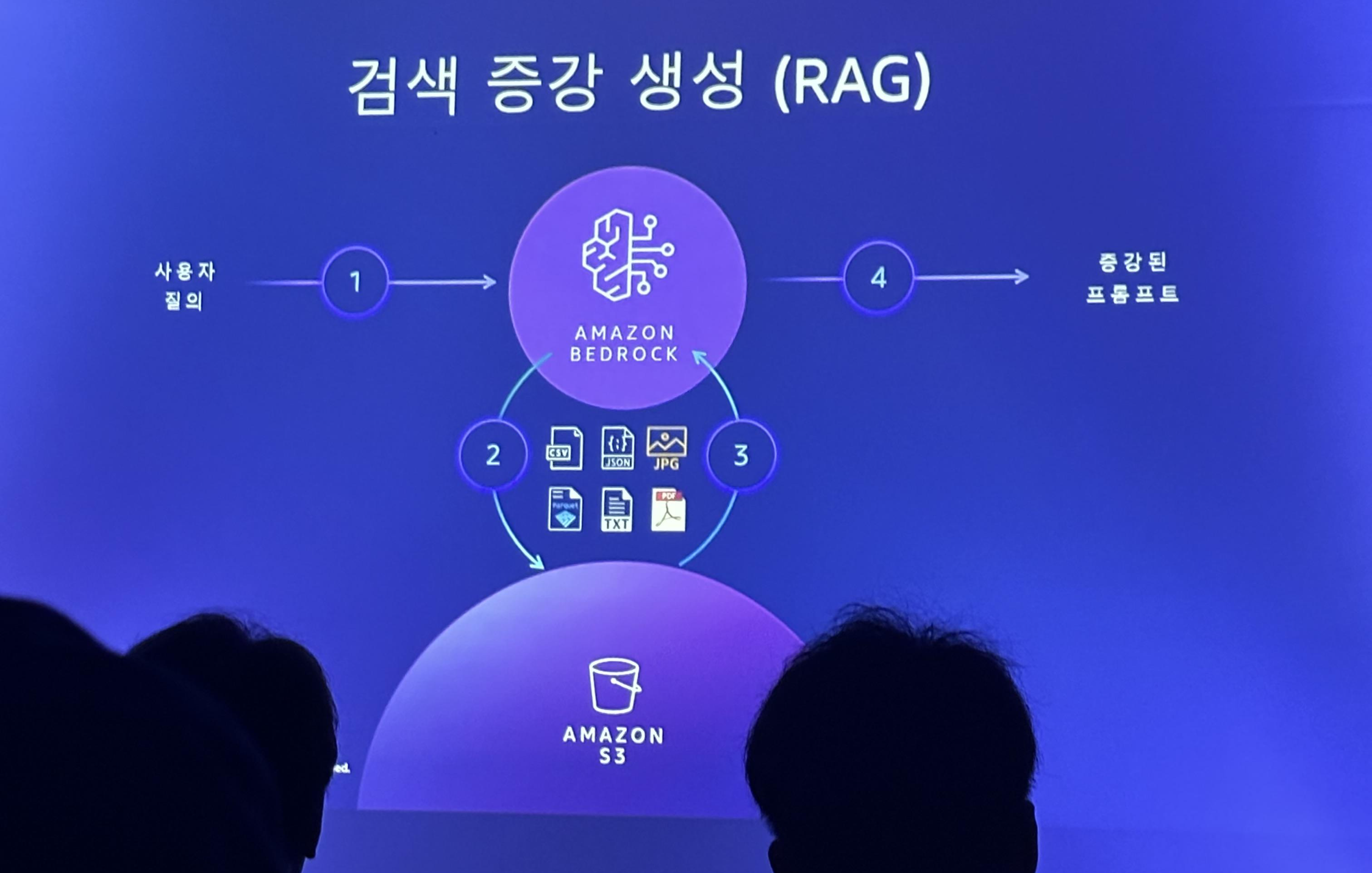
가장 쉬운 방법 중 하나는 기존에 있는 모델에 프롬프트를 보강하여 사용하는 RAG입니다.
- 검색(Retrieval) : 사용자 쿼리를 기반으로 외부 지식창고 또는 데이터 소스에서 관련 콘텐츠를 추출
- 증강(Augmentation) : 검색된 관련 컨텍스트를 사용자 프롬프트에 추가하여 파운데이션 모델에 입력으로 사용
- 생성(Generation) : 파운데이션 모델은 증강된 프롬프트에 기반해 응답
이는 Amazon 보험사 사례에서 잘 드러납니다. 예를 들어, 고객이 자동차보험에 대해 알아보고 싶어 할 때, RAG 모델은 다음과 같은 단계를 거칩니다:
- 어떤 고객인지 확인
- 필요한 정보들을 확인
- 정리하여 보험상품을 추천
- 견적 정보 확인
- 보장 옵션 안내
데이터 통합의 기술 스택
데이터 통합을 위한 기술 스택에는 다음과 같은 요소들이 포함됩니다:
- Redshift: 데이터 통합의 중심
- 데이터 수집과 처리: Amazon Apache Kafka (Amazon MSK), Kinesis, Amazon Apache Flink, Amazon EMR
- 대화 상태와 기록 저장: NoSQL, Document DB, Key/Value 모델
- 벡터 데이터 스토어: 스트리밍과 배치 수집 및 처리
사전 훈련된 모델의 미세 조정
사전 훈련된 모델을 비즈니스에 맞게 미세 조정하는 방법도 있습니다. 이는 RAG와 유사하게 데이터 통합을 중요시하며, 특정 비즈니스 요구에 맞춘 모델을 생성합니다. 이를 통해 더 정확하고 효율적인 AI 솔루션을 제공할 수 있습니다.
지속적 사전 훈련
지속적 사전 훈련은 조정된 데이터를 모델 자체에 포함시키는 방식입니다. Bedrock과 같은 플랫폼에서 테스트 문서를 임베딩으로 자동 변환하여 벡터 데이터베이스에 저장합니다. 이는 ETL(Extract, Transform, Load) 과정을 제거하고 서비스와 직접 통합하여 데이터를 활용할 수 있게 합니다. 또한, 서드파티 파트너와의 협력을 통해 데이터 활용 범위를 확장할 수 있습니다.
3. AWS 스토리지로 AI/ML 워크로드 가속화하기 (13:10 - 13:50)

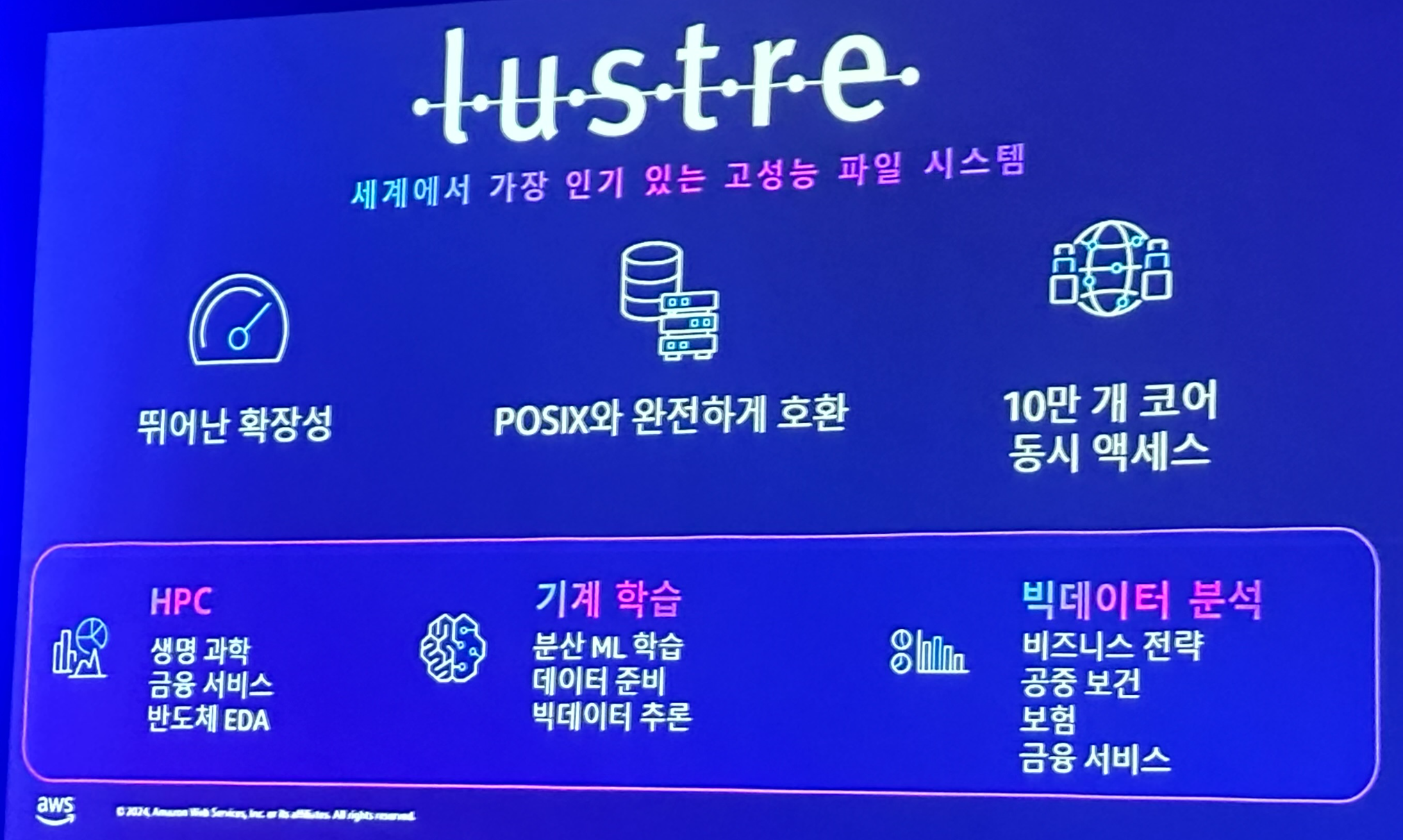
점심 시간 이후 진행된 두번째 세션은 AWS의 백승용, 정원진님이 생성형 AI를 위한 스토리지를 구성할 때 중요한 점을 발표하셨고, 이를 효과적으로 수행할 수 있는 lustre같은 오픈 소스도 소개해주셨습니다.
확산 모델의 발전과 클라우드 컴퓨팅의 발전은 인공지능의 진화와 밀접한 관련이 있습니다. ML 수명주기와 AWS 서비스의 통합은 데이터 관리와 비용 최적화를 통해 효율적인 AI 솔루션을 제공할 수 있도록 합니다.
[자세한 내용]
확산 모델의 발전
확산 모델의 발전은 GPU 기술의 발전과 맞물려 큰 진전을 이루었습니다. 컴퓨팅 기술의 발전은 인공지능의 진화와 함께 더욱 가속화되었습니다. 인공지능의 발전 단계는 다음과 같이 요약할 수 있습니다:
- 인공지능 (AI)
- 머신 러닝 (ML)
- 딥러닝/강화학습 (DL/RL)
- 생성형 AI (Generative AI)
이러한 발전 단계는 AI 기술의 복잡성과 성능을 점진적으로 향상시키며, 각 단계마다 더 큰 데이터와 더 강력한 컴퓨팅 자원을 요구하게 됩니다.
ML 수명주기 및 AWS 서비스
ML 수명주기는 준비 (Prepare), 구축 (Build), 훈련 (Train), 배포 (Deploy) 단계로 구성됩니다. 각 단계에서는 다음과 같은 AWS 서비스가 사용됩니다:
- SageMaker: ML 모델을 구축, 훈련, 배포하는 데 사용
- EC2: 확장 가능한 컴퓨팅 리소스를 제공
데이터셋이 점점 커짐에 따라 대용량 스토리지가 필요하며, 컴퓨팅 성능에 맞는 스토리지 성능이 요구됩니다. 특히, 체크포인트 시간을 최소화하는 것이 중요한데, 이는 스토리지 IO 성능을 최적화하는 것과 직결됩니다.
클라우드로의 여정
클라우드로의 전환은 다양한 스토리지 솔루션을 통해 이루어집니다:
- 리프트 & 시프트 파일 시스템
- S3 데이터레이크
- 오픈소스 Lustre: 대부분의 ML 애플리케이션과 호환되며, SageMaker 및 EC2와 통합됩니다.
Lustre는 연구원과 개발자에게 직관적이고 일관된 데이터 접근성을 제공하며, 빠르고 확장성이 뛰어난 랜덤 데이터 액세스를 지원합니다. 클라이언트 측면에서 인메모리 캐싱과 병렬 파일 시스템 성능을 제공합니다. 또한, 학습 워크로드에 대해 비용에 최적화된 다양한 가격 대비 성능 옵션을 제공합니다.
비용 최적화 방법
비용 최적화는 다음과 같은 방법을 통해 이루어집니다:
- 처리량 확장: 처리량 티어를 상향 또는 하향 조절
- 스토리지 타겟: 다양한 스토리지 클래스 제공을 통해 고객이 원하는 다양한 비용 옵션을 제공
SageMaker에서 S3 로딩 모드
SageMaker는 S3와 통합되어 빠른 파일 모드를 지원합니다. 이 모드를 사용하면 파일 다운로드 과정을 없앨 수 있으며, 예를 들어 파일 로딩 시간을 25분에서 5분으로 단축할 수 있습니다.
자체적 EC2 기반 ML 프레임워크
EC2 기반 ML 프레임워크 사용 시, PyTorch와 같은 프레임워크를 통해 데이터를 S3에 직접 저장할 수 있습니다:
- S3 -> 로컬 파일: 데이터 캐싱을 통해 리눅스 환경에서 파일을 관리할 수 있으며, 파일 수정은 지원되지 않습니다.
- 타임스탬프 기반 파일 관리: FSx for Lustre를 통해 캐싱 기능을 제공하고, S3 - ExpressOneZone PyTorch S3 커넥터를 사용하여 효율적으로 데이터를 관리할 수 있습니다.
4. 스마트한 미래, AWS와 함께하는 MongoDB Atlas 기반의 AI 애플리케이션 혁명 (14:20 - 14:50)
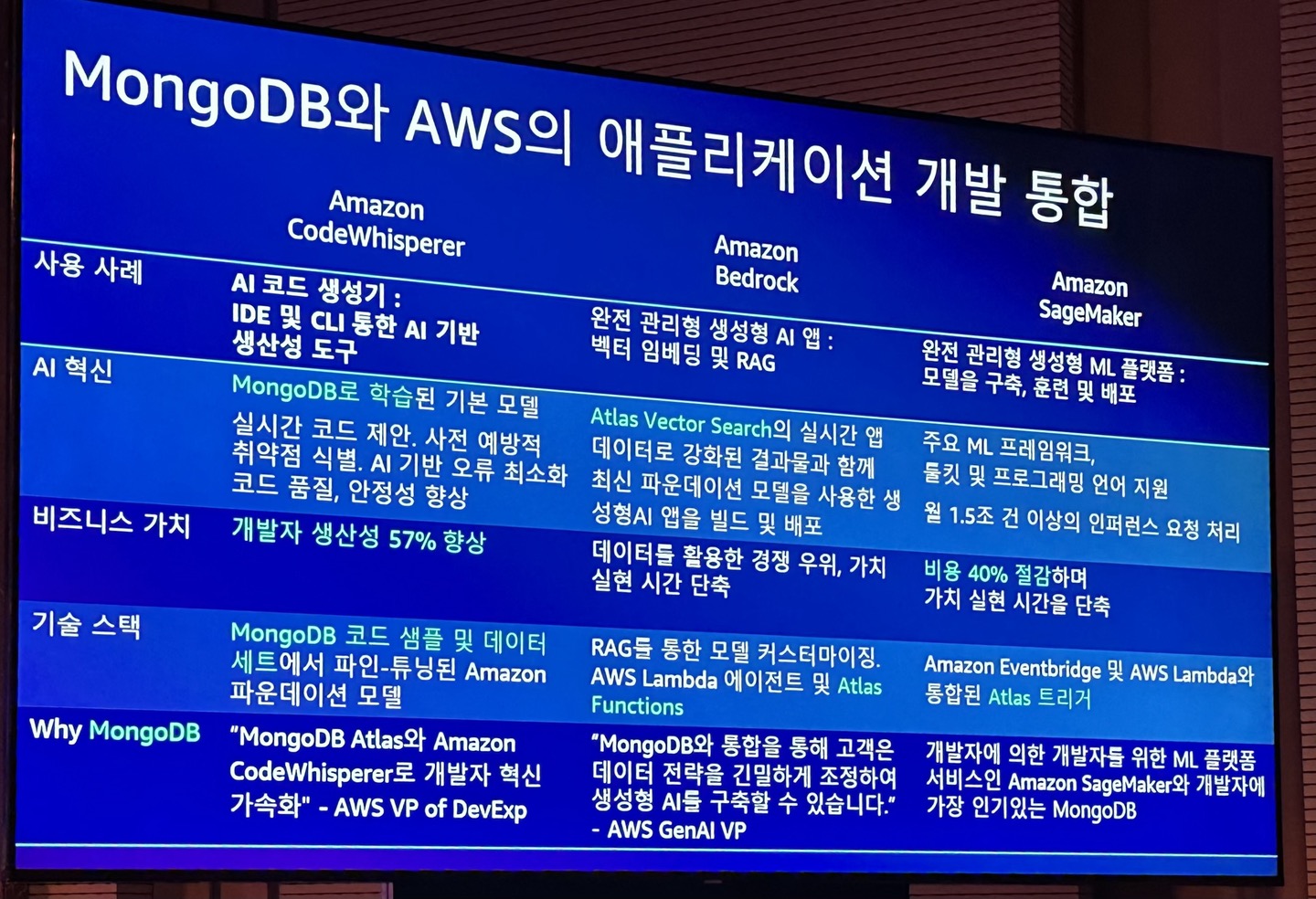
세번째 세션은 MongoDB의 김상필님, Syncly의 김진경님이 MongoDB와 AWS 서비스의 통합을 통한 효과적인 AI 솔루션을 만들어낸 과정과 그 장점에 대해 소개하고, Syncly에서 이를 어떻게 활용하였는지에 대해 설명하셨습니다.
AWS 인공지능 서비스와 MongoDB Atlas의 통합은 복잡성을 줄이고 빠르게 변화하는 비즈니스 환경에 유연하게 대응할 수 있는 솔루션을 제공합니다. Amazon Bedrock을 통해 생성형 AI 애플리케이션을 구축하고, MongoDB Atlas의 완전 관리형 서비스를 활용하여 데이터 관리와 AI 기능을 최적화할 수 있습니다. Syncly의 사례는 MongoDB Atlas의 유연성과 효율성을 잘 보여주며, 다양한 비즈니스 요구에 효과적으로 대응할 수 있는 통합 솔루션의 중요성을 강조합니다.
[자세한 내용]
통합의 배경 및 목표
AWS 인공지능 서비스와 MongoDB Atlas의 통합은 복잡한 부분을 줄이고 빠르게 변화하는 서비스에 대응하기 위해 이루어졌습니다. Amazon Bedrock을 통해 파운데이션 모델을 사용하여 생성형 AI 애플리케이션을 구축하고 이를 MongoDB와 통합함으로써 더욱 효율적인 데이터 관리와 AI 서비스를 제공할 수 있습니다.
Amazon Bedrock과 MongoDB Atlas 통합
Amazon Bedrock은 파운데이션 모델을 사용하여 생성형 AI 애플리케이션을 구축하는 플랫폼입니다. 이를 MongoDB와 통합하기 위해 별도의 VPC를 생성하여 보안과 성능을 보장합니다. MongoDB Atlas는 완전 관리형 서비스로서, 다양한 코딩 랭귀지와 함께 사용할 수 있어 개발자의 편의성을 높입니다. 특히, Atlas Vector Search는 도큐먼트 형태의 데이터뿐만 아니라 벡터 데이터까지 통합적으로 저장하고 관리할 수 있는 강력한 기능을 제공합니다.
Syncly의 MongoDB Atlas 선택 이유
Syncly의 테크 리드인 김진경 씨는 MongoDB Atlas를 선택한 이유에 대해 다음과 같이 설명했습니다:
1. 목표:
- 서비스 제공자는 고객의 니즈를 반영하여 이를 효율적으로 해결하고자 합니다.
- 비용 관리, 기술 지원, 글로벌 서비스 운영을 통해 서비스의 질을 높이고자 합니다.
2. 주요 관심사:
- 클라우드 플랫폼 선택
- 비즈니스 환경에 따른 데이터의 유동적 대응
- 글로벌 서비스 제공
- 지속적인 서비스 개선
3. MongoDB Atlas의 장점:
- No Schema: 1.2주 단위의 주간 스프린트를 통해 다양한 피드백을 비동기적으로 분석할 수 있습니다.
- Document 모델: Key-value 데이터 표현의 자유도는 높지만 키 관리가 어려운 문제를 해결할 수 있습니다. 따라서 Document 모델이 더욱 적합하다고 판단되었습니다.
- 텍스트 데이터 관리: 볼륨이 큰 텍스트 데이터를 관리하는 데 있어 컬렉션 인덱스는 비효율적이므로 MongoDB Atlas의 통합적인 데이터 관리가 큰 장점으로 작용합니다.
5. Amazon BedRock을 이용한 프롬프트 엔지니어링 모범사례 (15:20 - 16:00)

네번째 세션은 AWS의 김익수, 이홍주님이 프롬프트 엔지니어링 기법을 통해 생성형 AI의 답변의 정확성을 높이는 방법을 AWS Bedrock의 예시로 설명하고, Claude 서비스에 이 프롬프트 원칙을 적용하여 예시를 보여주셨습니다.
프롬프트 엔지니어링은 AI 응답의 정확성과 유용성을 높이는 중요한 도구입니다. 페르소나 설정, 특정 포맷으로의 답변 유도, 고급 기법 활용, 그리고 실험과 반복을 통해 최적의 프롬프트를 설계할 수 있습니다. 명확하고 직접적인 표현, 할루시네이션 방지, 그리고 고급 기법 활용을 통해 AI는 더 정확하고 유용한 응답을 제공할 수 있습니다. 이러한 가이드라인을 통해 복잡한 문제 해결 과정까지 포함하는 응답을 얻을 수 있으며, 이는 AI의 실용성을 극대화하는 데 도움이 됩니다.
[자세한 설명]
페르소나 설정의 중요성
프롬프트에 대한 AI의 응답은 설정된 페르소나와 역할에 따라 크게 달라질 수 있습니다. 예를 들어, 같은 질문이라도 페르소나가 물리 선생님일 때와 3살짜리 아이일 때의 응답은 다릅니다. 페르소나 설정은 AI의 태도와 응답 방식을 결정하는 데 중요한 요소입니다.
특정 포맷으로의 답변 유도
AI가 특정 포맷으로 답변하도록 유도하기 위해서는, 포맷의 첫 부분을 입력하는 방법을 사용할 수 있습니다. 이는 원하는 형식의 응답을 받기 위해 중요한 기술입니다.
고급 기법
프롬프트 엔지니어링에서는 다양한 고급 기법이 사용됩니다:
- Few-Shot Prompting: 몇 가지 예시를 제공하여 AI가 올바른 맥락을 이해하고 답변하도록 유도합니다.
- 증강형 프롬프트: 응답의 질을 높이기 위해 추가적인 정보를 제공하거나 질문을 세분화합니다.
- Chain of Thought: 복잡한 문제를 잘 풀기 위해 산출 과정을 추론하도록 유도하여 문제 해결 방법까지 제공받을 수 있습니다.
- RAG (Retrieval-Augmented Generation): S3에서 벡터 데이터(유사도 검색)를 사용하여 쿼리한 후, 이를 기반으로 응답을 생성합니다.
프롬프트 엔지니어링 가이드라인
프롬프트 엔지니어링을 최적화하기 위해 다음 가이드라인을 따릅니다:
- 경험적 과학: 프롬프트를 자주 테스트하고 반복하세요.
- 효율성: 모든 요소가 필요한 것은 아니지만, 처음에 많은 요소를 넣고 효율성을 위해 요소를 세분화하고 빼는 것이 가장 좋습니다. 실험과 반복이 핵심입니다.
- Claude 전용 프롬프트: AWS SA 김익수님의 조언에 따르면, 프롬프트는 명확하고 직접적으로 표현하는 것이 중요합니다. 생각하라는 XML 태그를 사용하여 아주 적은 양의 토큰으로도 높은 정확도를 달성할 수 있습니다.
할루시네이션(환각) 방지 방법
- 모르겠으면 모르겠다고 대답할 권한 부여
- 확신이 있는 경우에만 답변하도록 유도
- 1, 2 모두 수행해보고도 안 되면 인용문을 사용하여 답변
고급 프롬프트 기법
- Changing Prompts
- 200k Prompts
- Agents & Function Calling / Tool Use
- Search & RAG
6. Imply Druid를 활용한 실시간 데이터 분석과 당근마켓 사례 (16:30 - 17:00)
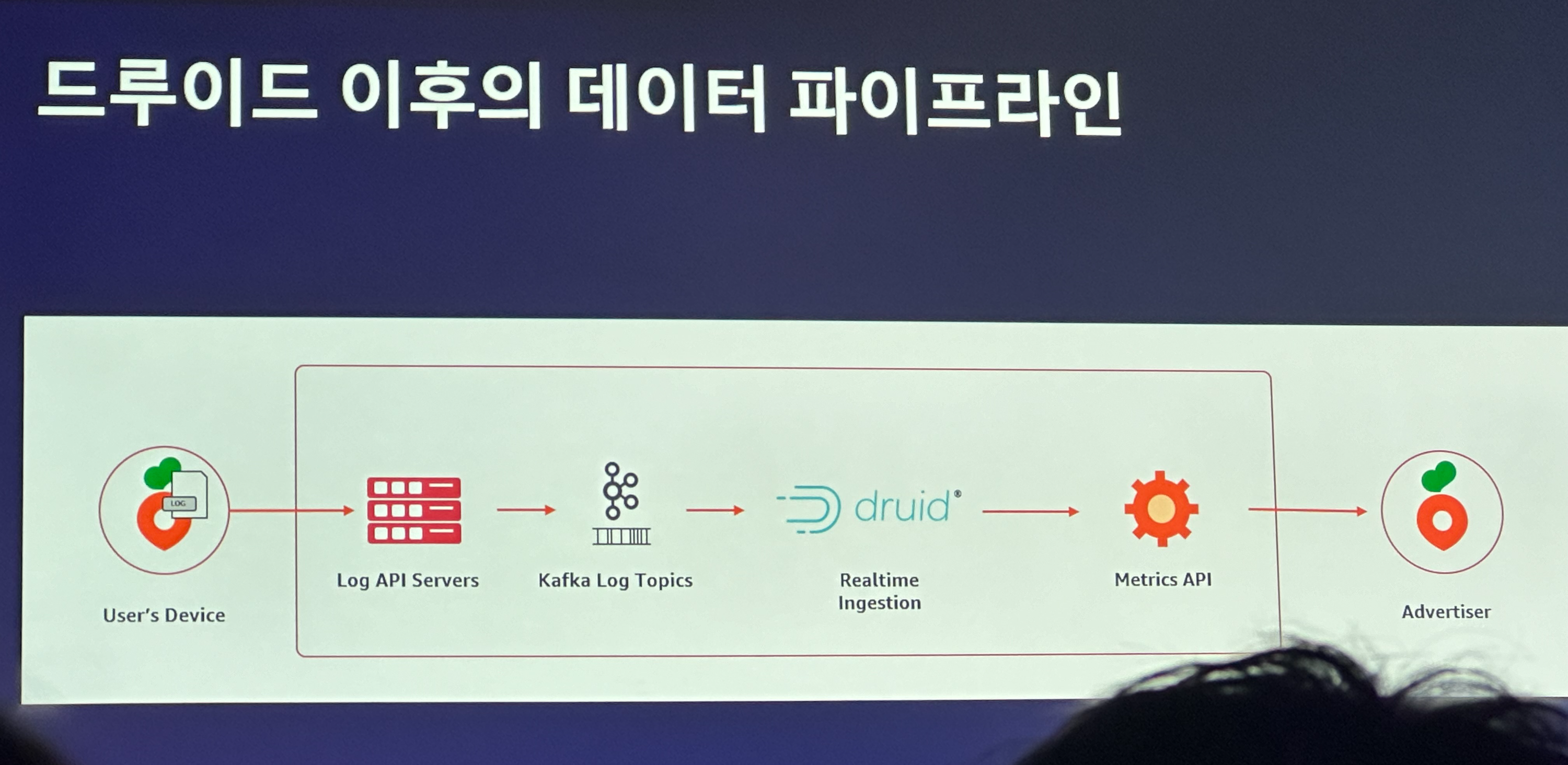
다섯번째 세션은 당근마켓의 노영진, Imply의 이기훈님이 이벤트 데이터를 실시간으로 보여줘야한다는 요구사항을 빠르게 해결하기 위해 Imply Apache Druid를 도입한 과정에 대해 설명해주셨다.
Imply와 Druid는 실시간 이벤트 데이터의 분석과 집계에 매우 효과적인 도구입니다. Kafka, Kinesis, Pulsar와 같은 메시징 플랫폼과 결합하여 강력한 데이터 분석 환경을 제공하며, 실시간 데이터와 히스토릭 데이터를 함께 분석할 수 있는 능력을 갖추고 있습니다. 국내에서는 당근마켓이 이를 통해 실시간 광고 성과를 분석하고 있으며, 다양한 타겟팅과 관리 기능을 통해 광고 효과를 극대화하고 있습니다. Druid의 도입으로 대용량 데이터를 효율적으로 처리하고 분석할 수 있는 능력을 확보하게 되었습니다.
[자세한 설명]
이벤트 데이터의 요구사항
이벤트 데이터는 실시간 분석과 집계가 필요하며, 이를 위해서는 이벤트 기반 메시지의 표준화가 중요합니다. 주로 사용되는 메시징 플랫폼으로는 Kafka, Kinesis, Pulsar가 있습니다. 이러한 플랫폼들은 데이터의 빠르고 안정적인 전송을 보장합니다.
Imply Druid를 통한 집계 및 분석
Imply Druid는 대규모 데이터의 실시간 집계와 분석을 위해 설계되었습니다. 이를 통해 분석 애플리케이션의 필요성을 충족할 수 있습니다:
- 1초 미만의 쿼리 응답 시간: 모든 쿼리에서 초 단위 미만의 응답 시간을 제공합니다.
- 높은 동시성: 최저 비용으로도 높은 동시성을 유지할 수 있습니다.
- 실시간 및 과거 데이터 통찰력: 실시간 데이터와 히스토릭 데이터를 함께 분석하여 통찰력을 제공합니다.
- 무중단 안정성: 자동화된 내결함성과 지속적인 백업을 통해 무중단 안정성을 보장합니다.
Imply의 활용 사례
Imply는 다양한 SASS 서비스 제공자들이 사용자 데이터를 수집하고 분석하는 데 사용됩니다. 예를 들어, Reddit은 사용자 검색에 맞는 광고를 노출하기 위해 Imply를 활용하고 있습니다. 국내에서는 당근마켓이 Imply를 도입하여 실시간 광고 성과를 분석하고 있습니다.
당근마켓의 실시간 광고 성과 분석 사례
노영진, 소프트웨어 엔지니어, 당근마켓
당근마켓은 광고플랫폼에서 실시간 데이터를 활용하여 연간 흑자를 달성하고 있습니다. 광고 실적의 99%는 지역광고, 검색광고, 전문가모드 플랫폼, 카탈로그 상품광고 출시 등에서 발생합니다. 특히 전문가모드 플랫폼에서는 셀프 서빙 광고 플랫폼으로서 목표 달성을 위해 필요한 다양한 타겟팅과 정교한 관리 기능을 제공합니다.
- 다차원 실시간 성과 조회: 지역, OS, 연령, 성별 별로 집계된 데이터를 실시간으로 보여주기 위해 Druid를 사용하기로 결정했습니다.
- 광고 타겟팅 기능: 성별, 연령, 관심사, OS 타겟팅 및 커스텀 타겟팅이 가능합니다. MAT 연동, 광고주 타겟 파일, 픽셀 등의 기능도 지원합니다.
Druid 도입의 효과
Druid 도입 이후 당근마켓은 1.5억 개의 이벤트를 실시간으로 처리할 수 있게 되었습니다. Druid의 주요 기능은 다음과 같습니다:
- 유연한 데이터 처리: 있을 수도 있고 없을 때도 있는 데이터를 효율적으로 처리합니다.
- 고성능: 대용량 보고서 다운로드 시에도 성능 저하를 느끼지 못합니다.
- 편리한 분석 도구: 피벗 테이블 툴이 유용하여 대규모 데이터의 분석이 용이합니다.
7. 부스 탐방
이번에도 다양한 부스들이 열렸습니다. 저는 AWS의 체험 부스를 특히 재밌게 즐겼습니다.




다양한 강의와 체험 부스를 재미있게 즐길 수 있었던 AWS Summit 2024의 후기는 여기까지 입니다.
AWS Summit 2025가 기다려집니다!
긴 글 읽어주셔서 감사합니다.
'Cloud' 카테고리의 다른 글
| [NCP] 네이버클라우드 NCE 자격증 후기 + 공부 방법 (6) | 2022.12.15 |
|---|---|
| [NCP] 존, 리전 개념에 대해서 (2) | 2021.07.14 |

